
As published on the UK Web Archive blog.
I gave the following presentation at the 2015 IIPC GA. If you prefer, you can read the rough script with slides (below the fold) rather than watch the video.


We started archiving websites by permission towards the end of 2004 (e.g. The Hutton Enquiry), building up what we now call the Open UK Web Archive. In part, this was considered a long-term investment, helping us build up the skills and infrastructure we need to support large-scale domain crawls under non-print Legal Deposit legislation, which we’ve been performing since 2013.
Furthermore, to ensure we have as complete a record as possible, we also hold a copy of the Internet Archives’ collection of .uk domain web material up until the Legal Deposit regulations were enacted. However these regulations are going to be reviewed, and could, in principle, be withdrawn. So, what should we do?
To ensure the future of these collections, and to reach our goals, we need to be able to articulate the value of what we’ve saved. And to do this, we need a better understanding of our collections and how they can be used.
Understanding Our Collections #
So, if we step right back and just look at those 8 billion resources, what do we see? Well, the WARCs themselves are just great big bundles of crawled resources. They reflect the harvester and the bailer, not the need.

So, at the most basic level, we need to be able to find things and look at them, and we use OpenWayback to do that. This example shows our earliest archived site, reconstructed from the server-side files of the British Library’s first web server. But you can only find it if you know that the British Library web site used to be hosted at “portico.bl.uk”.
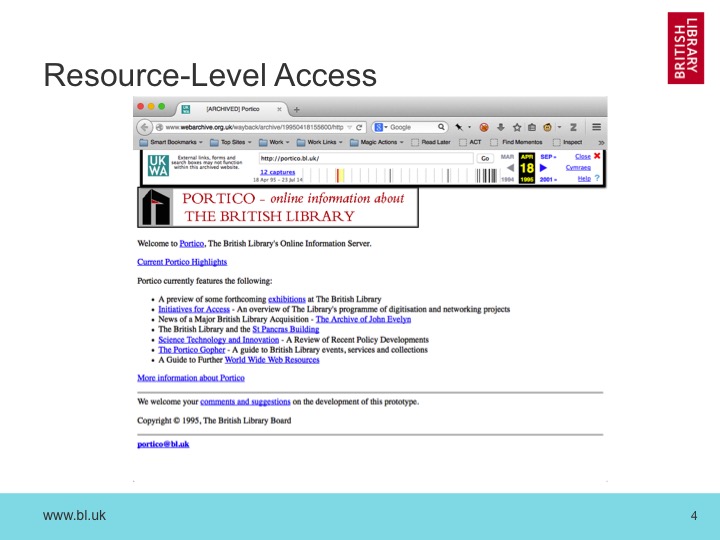
But that mode of access requires you to know what URLs you are interested in, so we have also built up various themed collections of resources, making the archive browsable.

However, we’re keenly aware that we can’t catalog everything.
To tackle this problem, have also built full-text indexes of our collections. In effect, we’ve built an historical search engine, and having invested in that level of complexity, it has opened up a number of different ways of exploring our archives. The “Big Data Research” panel later today will explore this in more detail, but for now here’s a very basic example.
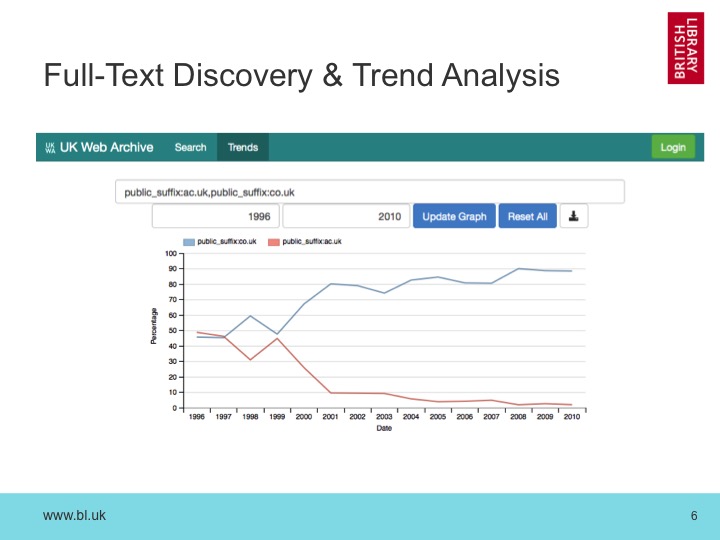
This graph show the fraction of URLs from ac.uk hosts and co.uk hosts over time. We can see that back in 1996, about half the UK domain was hosted on academic servers, but since then co.uk has come to dominate the picture. Overall, in absolute terms, both have grown massively during that period, but as a fraction of the whole, ac.uk is much diminished. This is exactly the kind of overall trend that we need to be aware of when we are trying to infer something from a more specific trend, such as the prevalence of medical terms on the uk web.
However, these kinds of user interfaces are hard to build and are forced to make fairly strong assumptions about what the user wants to know. So, to complement our search tools, we also generate various secondary datasets from the content so more technically-adept users can explore our data using their own tools. This provides a way of handing rich and interesting data to researchers without handing over the actual copyrighted content, and has generated a reasonable handful of publications so far.

This process also pays dividends directly to us, in that the way researchers have attempted to exploit our collections has helped us understand how to do a better job when we crawl the web. As a simple example, one researcher used the 1996 link graph to test his new graph layout algorithm, and came up with this visualization.

For researchers, the clusters of connectivity are probably the most interesting part, but for us, we actually learned the most from this ‘halo’ around the edge. This halo represent hosts that a part of the UK domain, but are only linked to from outside the UK domain. Therefore, we cannot build a truly representative picture of the UK domain unless we allow ourselves to stray outside it.
The full-text indexing process also presents an opportunity to perform deeper characterization of our content, such as format and feature identification and scanning for preservation risks. This has confirmed that the vast majority of the content (by volume) is not at risk of obsolescence at the format level, but has also illustrated how poorly we understand the tail of the format distribution and the details of formats and features that are in use.
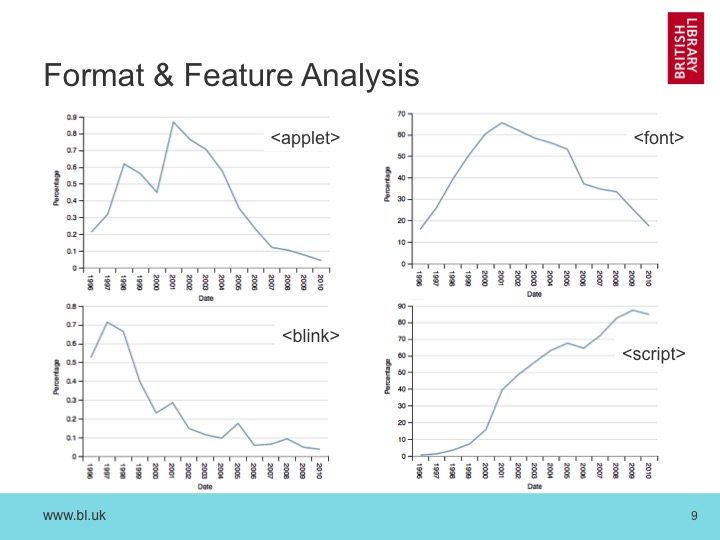
For example, we also build an index that shows which tags are in use on each HTML page. This means we can track the death and birth of specific features like HTML elements. Here, we can see the death of the <applet>, <blink> and <font> tags, and the massive explosion in the usage of the <script> tag. This helps us understand the scale of the preservation problems we face.
Putting Our Archives In Context #
But all this is rather inward looking, and we wanted to find ways of complementing these approaches by comparing our collections with others and especially with the live web. This is perhaps the most fundamental way of stating the value of what we’ve collected as it addresses the basic quality of the web that we need to understand - it’s volatility.

How has our archival sliver of the web changed? Are the URLs we’ve archived still available on the live web? Or are they long since gone? If those URLs are still working, is the content the same as it was?
One option would be to go through our archives and exhaustively examine every single URL to work out what has happened to it. However, the Open UK Web Archive contains many millions of archived resources, and even just checking their basic status would be very time-consuming, never mind performing any kind of detailed comparison of the content of those resources.
Sampling The URLs #
Fortunately, to get a good idea of what has happened, we don’t need to visit every single item. We can use our index to randomly sample a 1000 URLs from each year the archive has been in operation. We can then try to download those URLs again, and use the results to build up a picture that compares our archival holdings to the current web.

As we download each URL, if the host has disappeared, or the server is unreachable, we say its GONE. If the server responds with an ERROR, we record that. If the server responds but does not recognize the URL, we classify it as MISSING, but if the server does recognize the URL, we classify it as MOVED or OK depending on whether a chain of redirects was involved. Note that we did look for “Soft 404s” at the same time, but found that these are surprisingly rare on the .uk domain.
Plotting the outcome by year, we find this result:
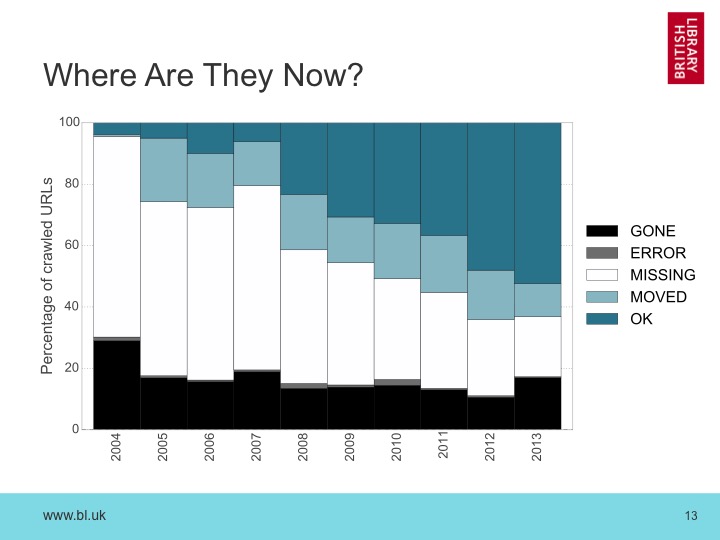
The overall trend clearly shows how the items we have archived have disappeared from the live web, with individual URLs being forgotten as time passes. Looking at 2013, even after just two years, 40% of the URLs are GONE or MISSING.
Is OK okay? #
However, so far, this only tells us what URLs are still active - the content of those resources could have changed completely. To explore this issue, we have to dig a little deeper by downloading the content and trying to compare what’s inside.
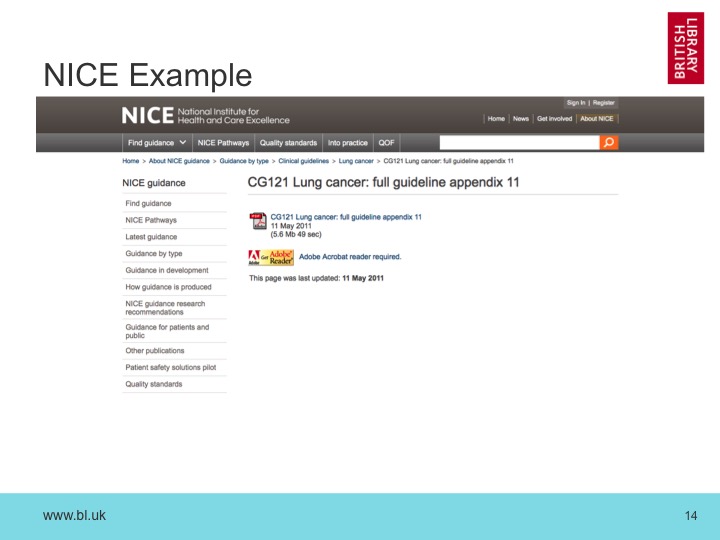
We start by looking at a simple example - this page from the National Institute for Health and Care Excellence. If we want to compare this page with an archived version, one simple option is to ignore the images and tags, and just extract all the text.

However, comparing these big text chunks is still rather clumsy and difficult scale, so we go one step further and reduce the text to a fingerprint1.
A fingerprint is conceptually similar to the hashes and digests that most of us are familiar with, like MD5 or SHA-256, but with one crucial difference. When you change the input to an cryptographic hash, the output changes completely - there’s no way to infer any relationship between the two, and indeed it is that very fact that makes these algorithms suitable for cryptography.

For a fingerprint, however, if the input changes a little, then the output only changes a little, and so it can be used to bring similar inputs together. As an example, here are our fingerprints for out test page – one from earlier this year and another from the archive. As you can see, this produces two values that are quite similar, with the differences highlighted in red. More precisely, they are 50% similar as you’d have to edit half of the characters to get from one to the other.
To understand what these differences mean, we need to look at the pages themselves. If we compare the two, we can see two small changes, one to the logo and one to the text in the body of the page.
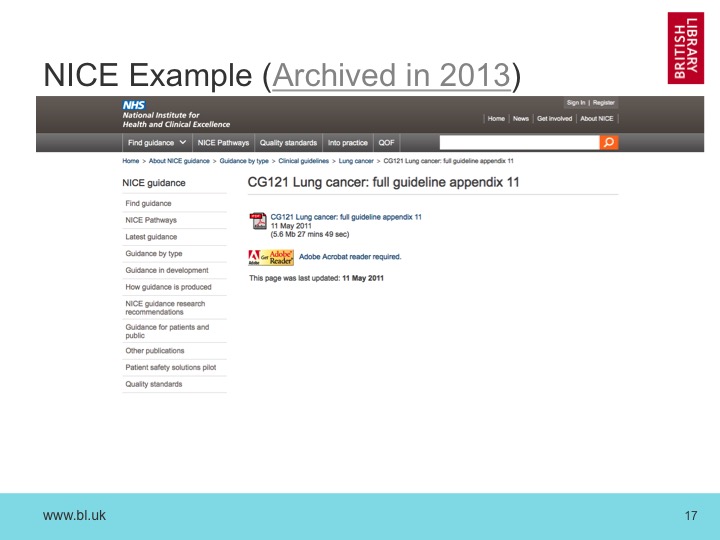
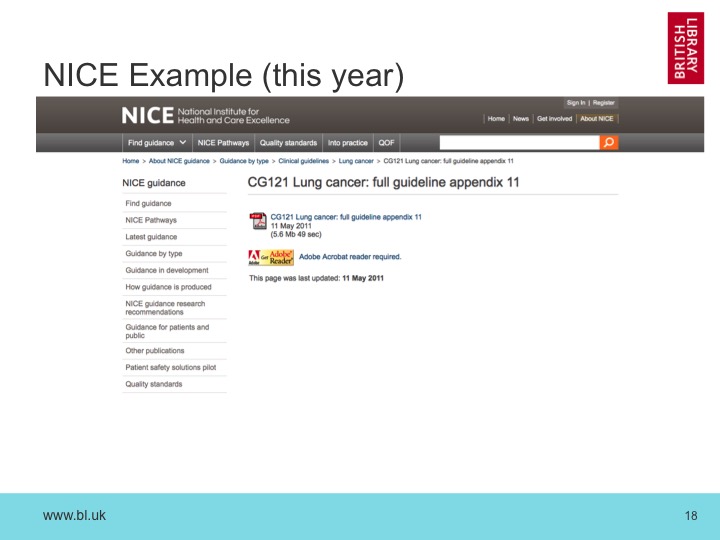
But what about all the differences at the end of the fingerprint? Well, if we look at the whole page, we can see that there are major differences in the footer. In fact, it seems the original server was slightly mis-configured when we archived it in 2013, and has accidentally injected a copy of part of the page inside overall page HTML.
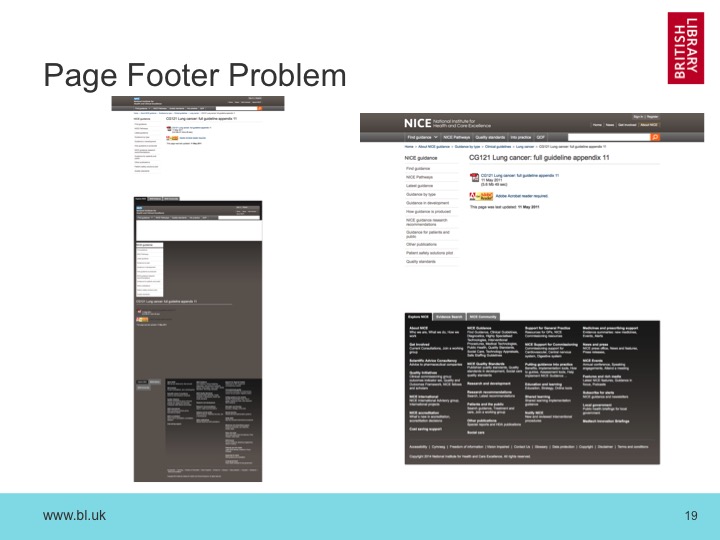
So, this relatively simple text fingerprint does seem to reliably reflect both the degree of changes between versions of pages, and also where in the pages those changes lie.
Processing all of the ‘MOVED’ or ‘OK’ URLs in this way, we find:
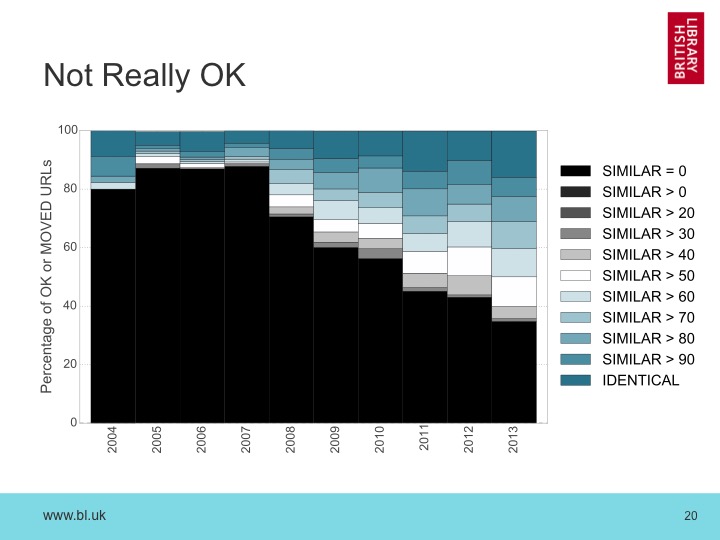
We can quickly see that for those URLs that appeared to be okay, the vast majority have actually changed. Very few are binary identical, and while about half of the pages remain broadly similar after two years, that fraction tails off as we go back in time.
We can also use this tactic to compare the OK and MOVED resources.
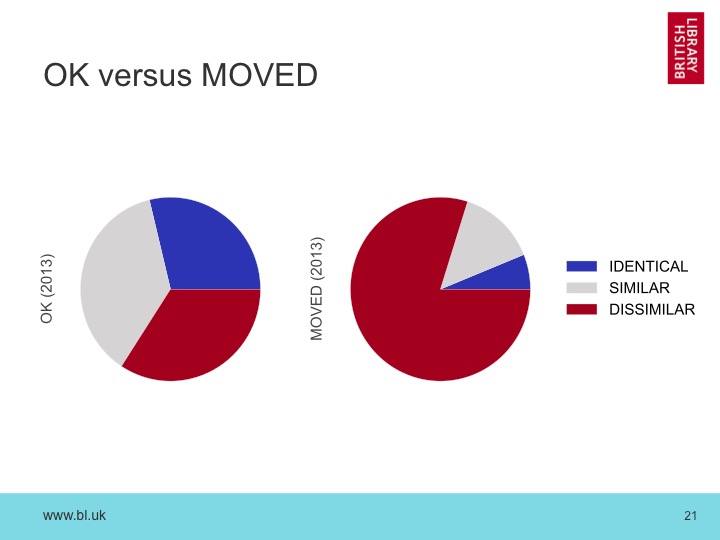
For resources that are two years old, we find that URLs that appear to be OK are only identical to the archived versions one third of the time, similar another third of the time, but the remaining third are entirely dissimilar. Not surprisingly, the picture is much worse for MOVED URLs, which are largely dissimilar, with less than a quarter being similar or identical.
The URLs Ain’t Cool #
Combining the similarity data with the original graph, get this result:
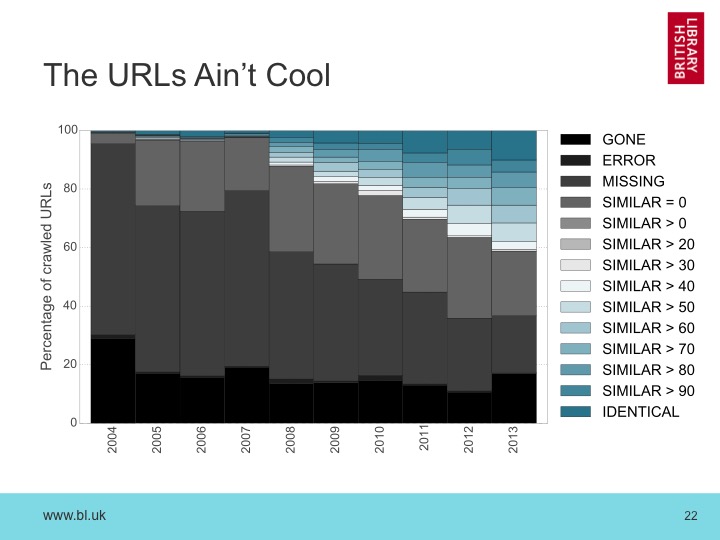
Shown in this way, it is clear that very few archived resources are still available, unchanged, on the current web. After just two years, 60% have gone or have changed into something unrecognizable.2
This rot rate is significantly higher than I expected, so I began to wonder whether this a kind collection bias. The Open UK Web Archive often prioritized sites known to be at risk, and that selection criteria seems likely to affect the overall trends. So, to explore this issue, I also ran the same analysis over a randomly sampled subset of our full, domain-scale Legal Deposit collection.
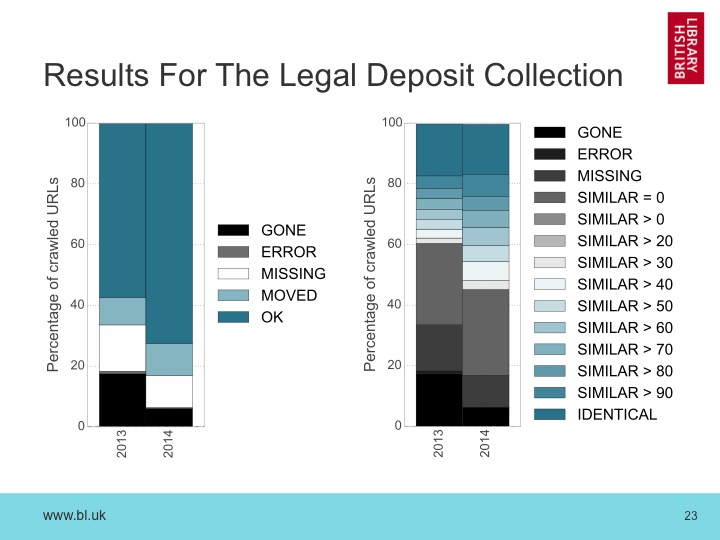
However, the results came out almost exactly the same. After two years, about 60% of the content has GONE or is unrecognizable. Furthermore, looking at the 2014 data, we can see that after just one year, although only 20% of the URLs themselves have rotted, a further 30% of the URLs are unrecognizable. We’ve lost half the UK web in just one year.
This raised the question of whether this instability can be traced to specific parts of the UK web. Is ac.uk more stable than co.uk, for example?
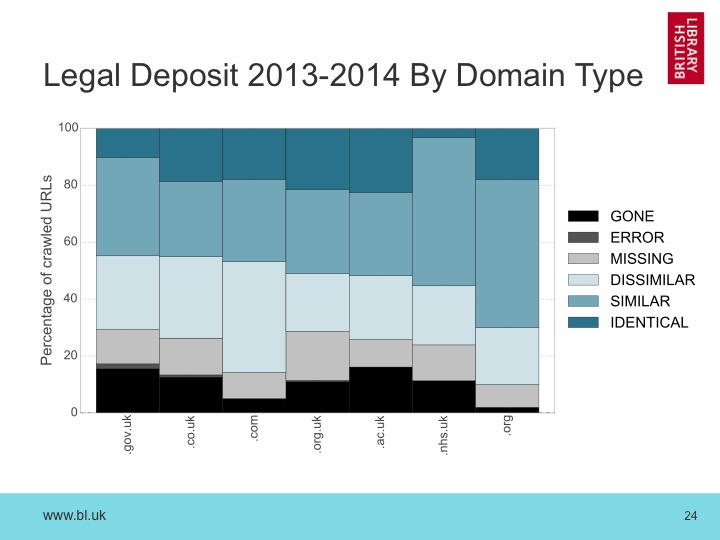
Looking at those results showed that, in fact, there’s not a great deal to choose between them. The changes to the NHS during 2013 seem to have had an impact on the number of identical resources, with perhaps a similar story for the restructuring of gov.uk, but there’s not that much between all of them.
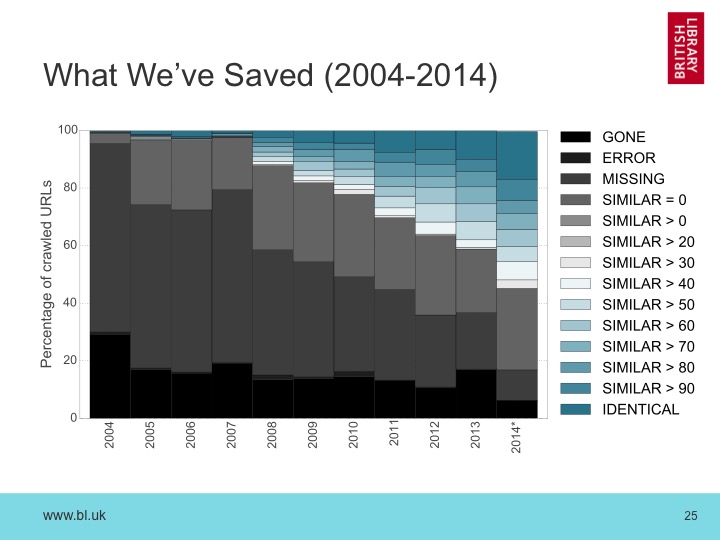
What We’ve Saved (2004-2014) #
Pulling the Open and Legal Deposit data together, we can get an overview of the situation across the whole decade. For me, this big, black hole of content lost from the live web is a powerful way of visualizing the value of what we’ve saved over those ten years.
Summary #
I expected the rot rate to be high, but I was shocked by how quickly link rot and content drift come to dominate the scene. 50% of the content is lost after just one year, with more being lost each subsequent year. However, it’s worth noting that the loss rate is not maintained at 50%/year. If it was, the loss rate after two years would be 75% rather than 60%. This indicates there are some islands of stability, and that any broad ‘average lifetime’ for web resources is likely to be a little misleading.
We’ve also found that this relatively simple text fingerprint provides some useful insight. It does ignore a lot, and is perhaps overly sensitive to changes in the ‘furniture’ of a web site, but it’s useful and importantly, scalable.
There are a number of ways we might take this work forward, but I’m particularly interested in looking for migrated content. These fingerprints and hashes are in our full-text index, which means we can search for similar content that has moved from one URL to another even if the was never any redirect between them. Studying content migration in this way would allow us to explore how popular content moves around the web.
I’d also like to extend the same sampling analysis in order to compare our archives with those of other institutions via the Memento protocol.

Thank you, and are there any questions?
Addendum #
If you’re interested in this work you can find:
- The video of my presentation on YouTube
- The slides on slideshare or on speakerdeck.
- The source code for the data generation, halflife.
- The iPython Notebook used to generate the graphs, half-life.ipynb.
-
This technique has been used for many years in computer forensics applications, such as helping to identify ‘bad’ software, and here we adapt the approach in order to find similar web pages. ↩︎
-
Or, in other words, very few of our archived URLs are cool. ↩︎