
Four years ago, during the 2012 IIPC General Assembly, we came together to discuss the recent and upcoming challenges to web archiving in the Future of the Web Workshop (see also this related coverage on David Rosenthal’s blog). That workshop made it clear that our tools are failing to satisfy many of these challenges:
- Database driven features
- Complex/variable URI formats
- Dynamically generated URIs
- Rich, streamed media
- Incremental display mechanisms
- Form-filling
- Multi-sourced, embedded content
- Dynamic login, user-sensitive embeds
- User agent adaptation
- Exclusions (robots.txt, user-agent, …)
- Exclusion by design (i.e. site architecture intended to inhibit crawling and indexing)
- Server-side scripts, RPCs
- HTML5 web sockets
- Mobile sites
- DRM protected content, now part of the HTML standard
- Paywalls
I wish I could stand here and tell you how much great progress we’ve made in the last four years, ticking entries off this list, but I can’t. Although we’ve made some progress, our crawl development resources have been consumed by more basic issues. We knew moving to domain crawling under Legal Deposit would bring big changes in scale, but I’d underestimated how much the dynamics of the crawl workflow would need to change.
News websites are a great example.
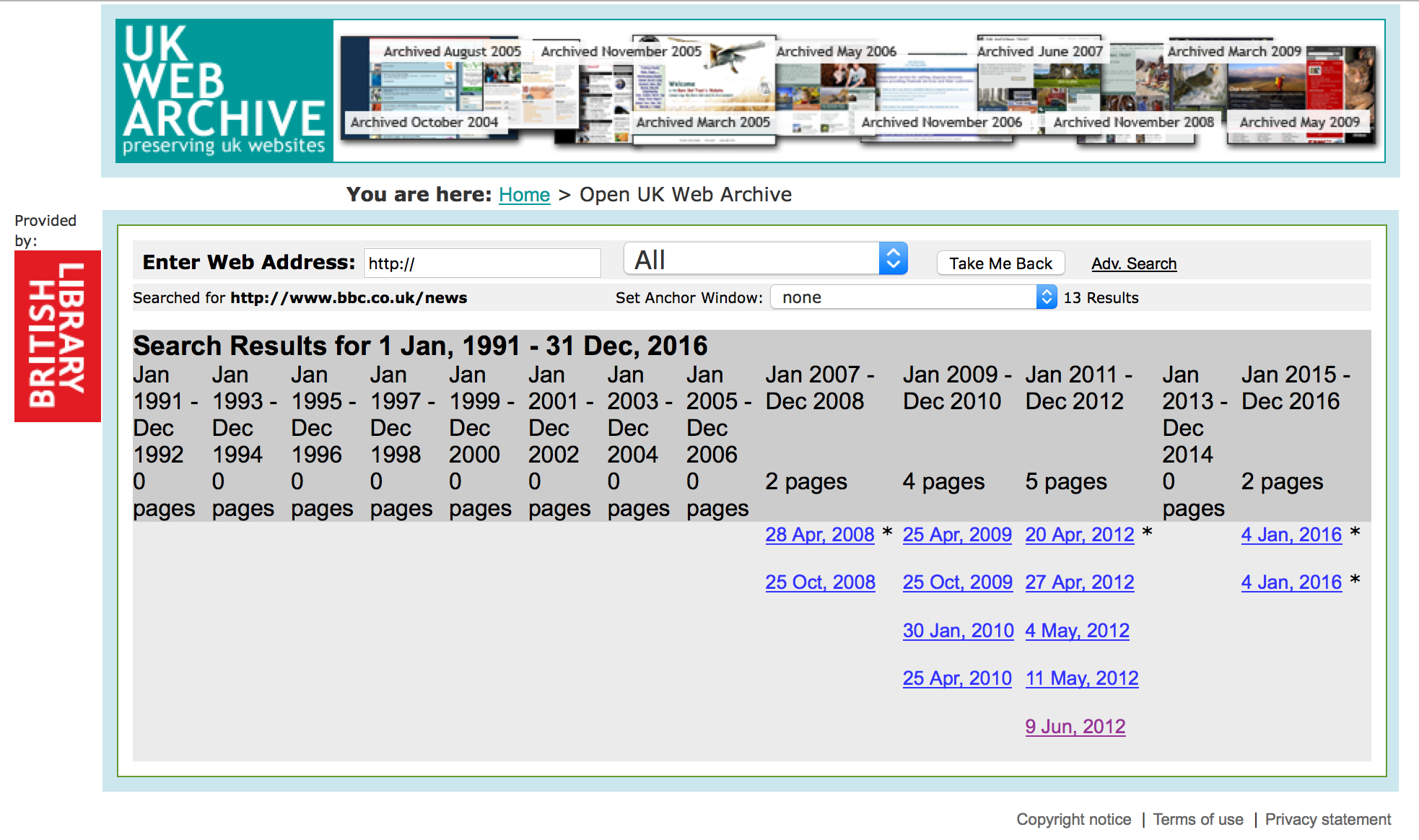
Under selective archiving, we would generally only archive specific articles, relating to themes or events. For example, since 2008, we had captured just 13 snapshots of BBC News home page and just a few hundred individual news articles.
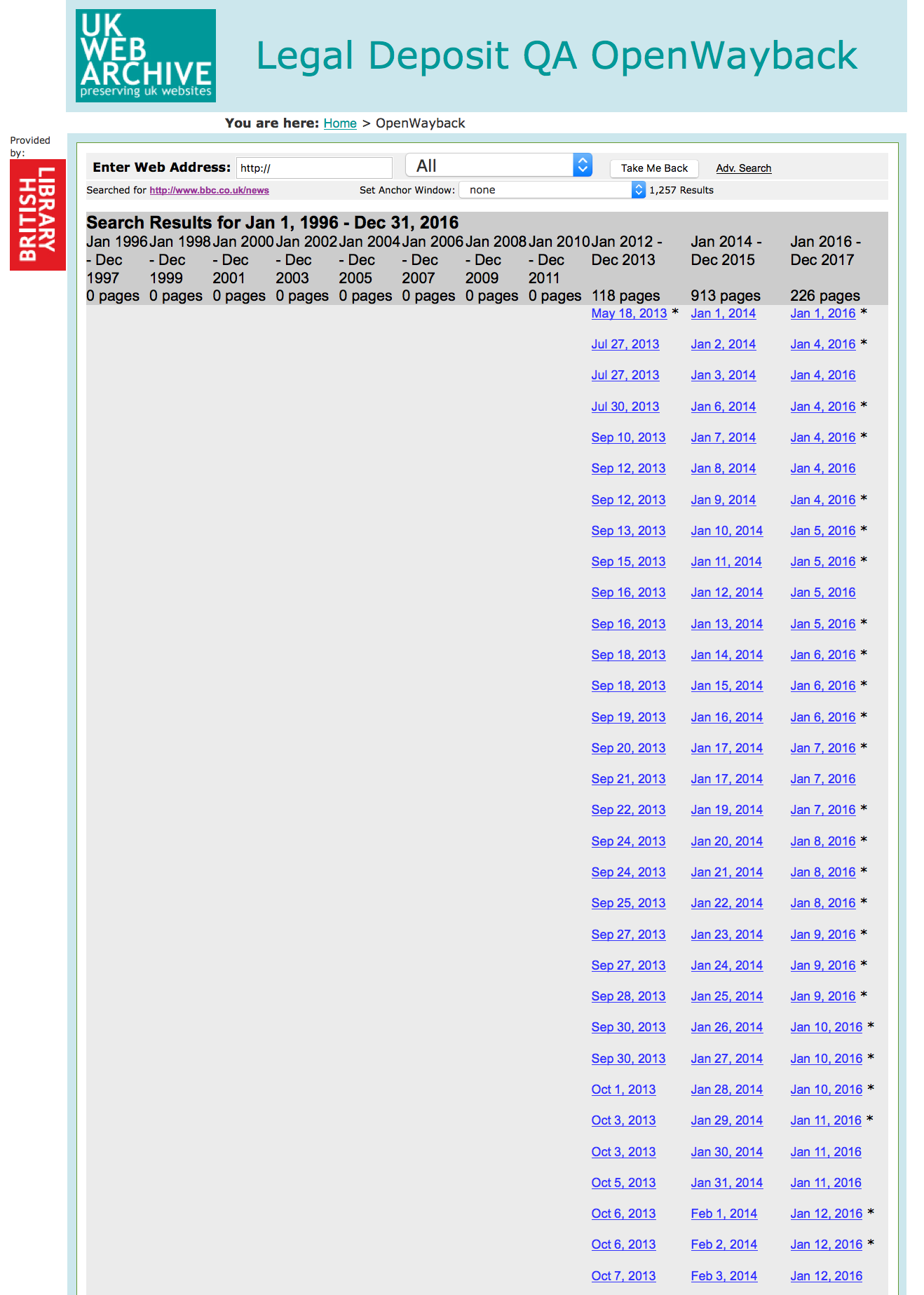
Under Legal Deposit, we expect to archive every single news article. This means we need to visit each news site at least once a day, and ideally more frequently than that, while also going back and re-crawling everything at least once every few months in case the content or presentation is changed.
Our first large-scale ‘frequent crawler’ worked by re-starting the whole crawl job every time, but this stop-start approach meant the sites we visited very frequently would never be crawled very deeply - it’s obviously impossible to crawl all of BBC News in a day. The problem was the need to capture both depth and frequent changes.
One approach would have been to create many different crawl jobs for different combinations of sites, depths and frequencies, but this ran into our second problem - the poor manageability of our tools and workflows. Managing multiple overlapping jobs in Heritrix has proven to be awkward, needing a lot of manual intervention to move different jobs around in order to balance out resource usage over time.1 As well as being difficult to fully automate, multiple jobs are also more difficult to monitor effectively.
We’ve learned that everything that can automated should be, and must also be seen to be working. This is not just monitoring uptime or disk space, but runs all the way up to automating quality assurance wherever possible.
However, while exploring how to improve our automated QA, we met the third problem. Our tools were failing to archive the web, making automated QA irrelevant. Not only are our tools difficult to configure, manage and monitor, but they have also fallen too far behind current web development practices. Many of those ‘future web challenges’ we talked about in 2012, are here, now.
Here’s the BBC News homepage on the 20th of March last year:
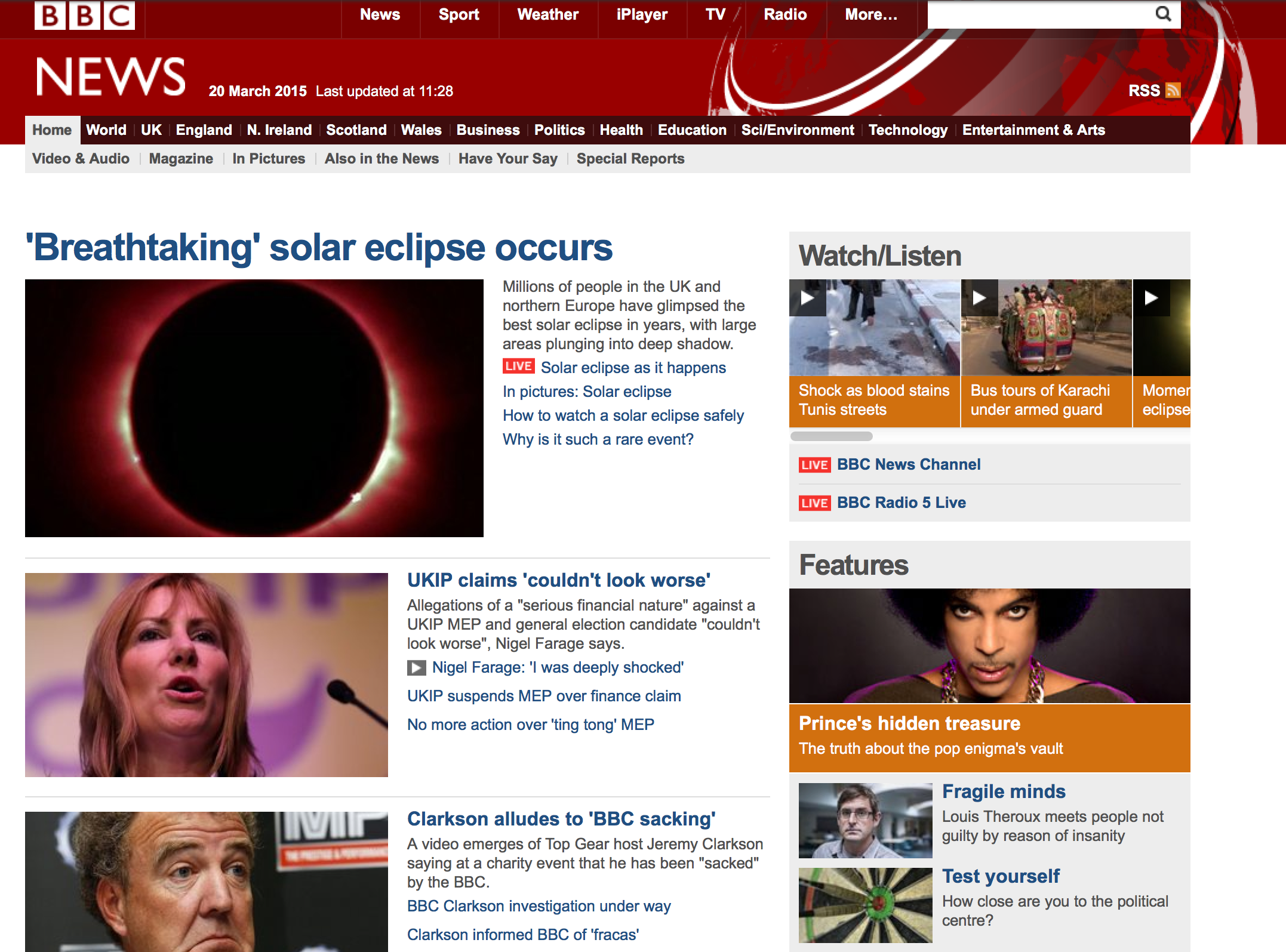
And here it is four days later:
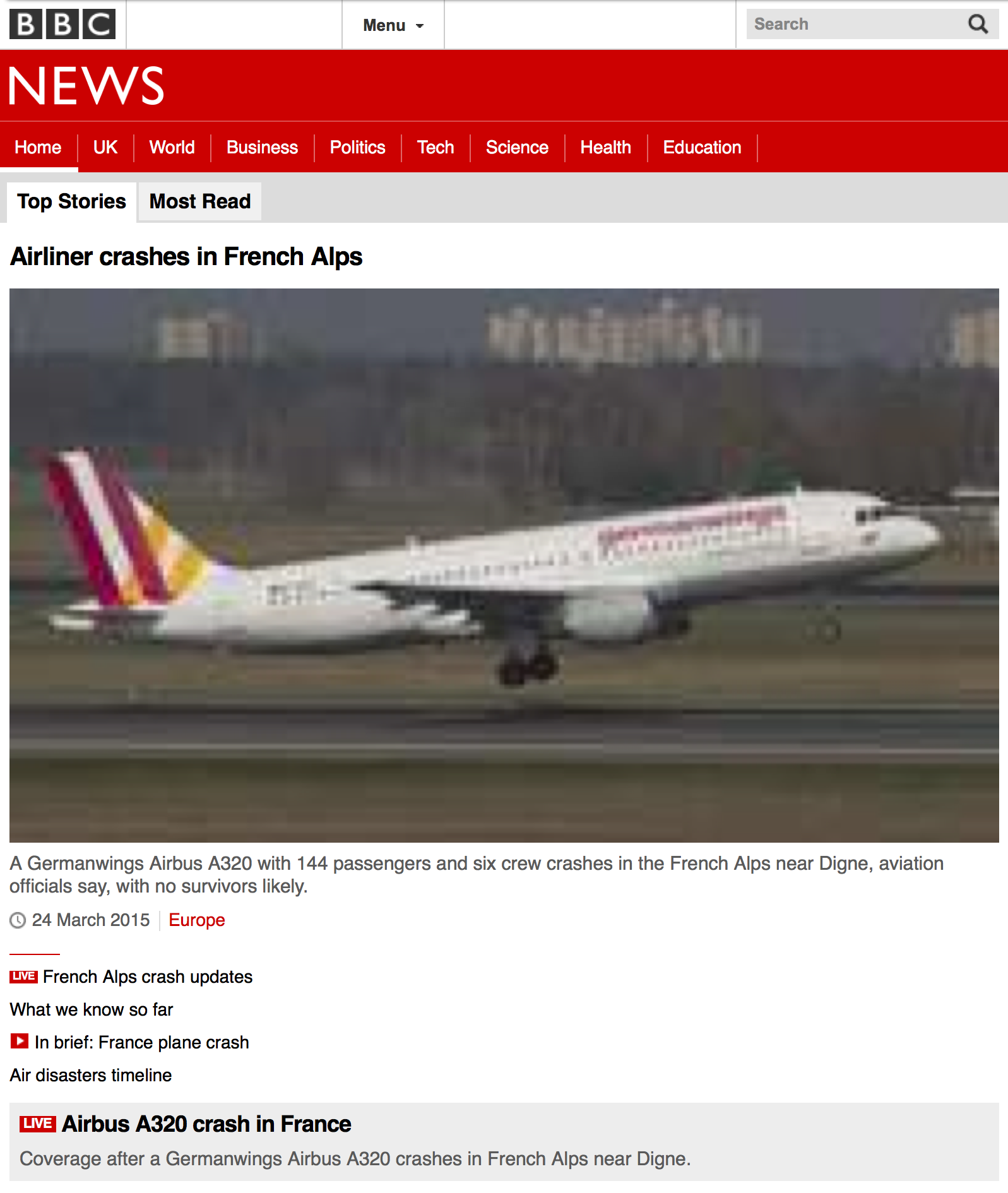
We knew the growth in mobile browsing would change the web, and in this case the problems are due to the BBC’s adoption of “responsive design”. Like many other sites, they now use JavaScript to adapt to different displays, although they have aggressively optimised for mobile first. The site delivers a basic, functional page (with only a few low resolution images), but then uses JavaScript to enhance the display by loading in different stylesheets and more, higher resolution images. Our Heritrix only got the version intended for very small screens.

A more representative example of these issues comes from The Guardian. Their responsive design was more standard and used the srcset attribute on images to provide different resolution versions. However, even though the srcset image attribute has been around since 2012 and implemented widely since 2014, it’s still not supported by Heritrix out-of-the-box and has only just become supported by OpenWayback (in version 2.3.1).

In summary, we needed a new crawl process that:
- Crawls more often as well as crawling sites deeply.
- Is easier to develop, monitor and managed.
- Uses a browser to render at least the main seed URLs in order to capture more dependencies.
To do this, we’ve changed our crawling process away from being based on crawl jobs, and instead we run one continuous crawl. In order to launch crawls for new material, we inject seeds into the crawl as part of an overall workflow. The workflow attempts to break the overall crawl process down into smaller, separate processes that perform individual crawl tasks, and then we join them together using a standard message queue system.
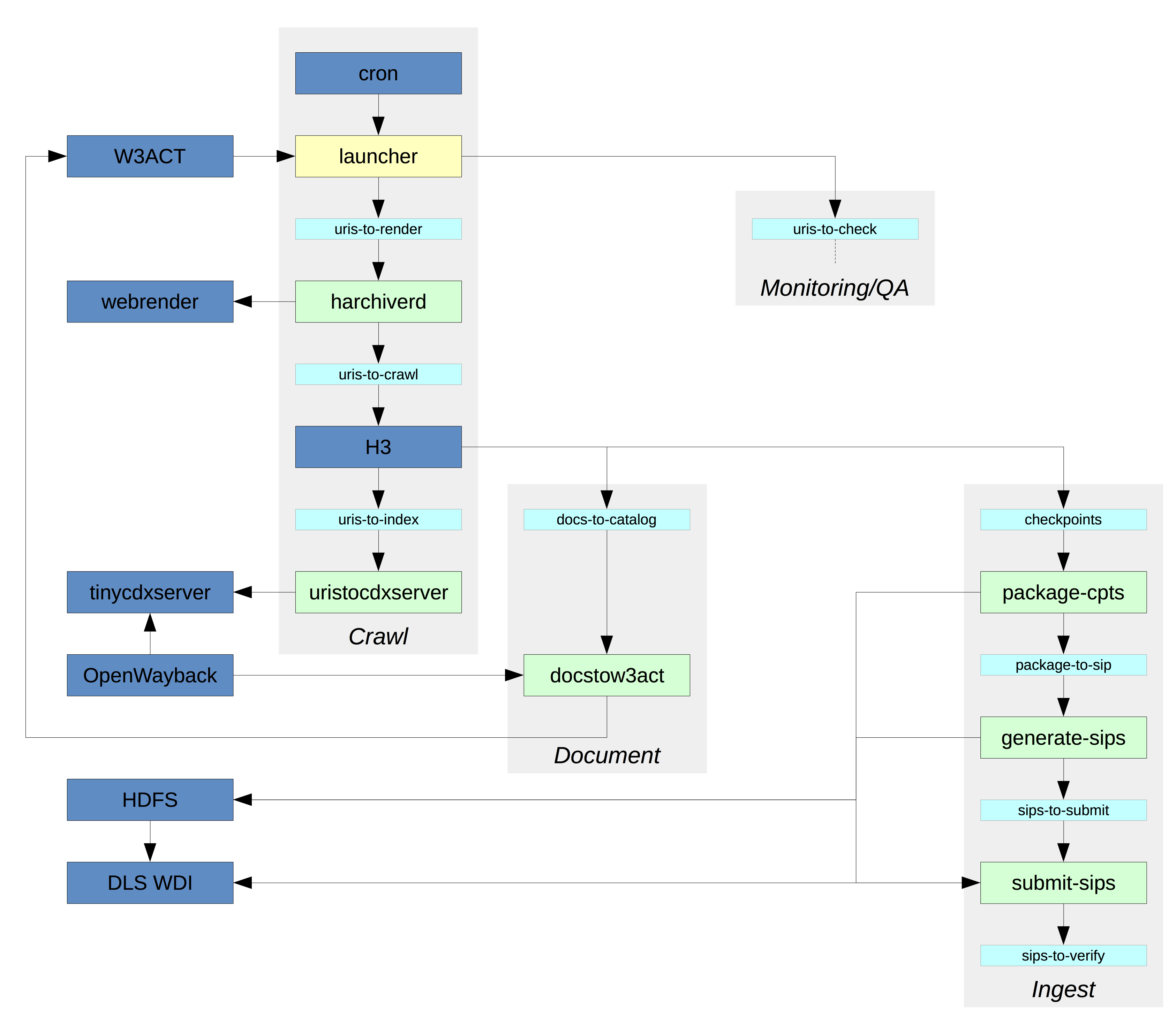
This architectural pattern, with relatively simple processes joined together with queues acting as buffers, is fairly common in mainstream distributed computing systems. As long as clear APIs are defined that describe how each microservice talks to the next, the individual components and be restarted, upgraded or replaced without bringing down the whole system. This chain of messages also provides a handy way of monitoring the overall progress of the crawl. This approach also encourages a more modular design, where each component has a clear role and function, so that it’s easier to understand what’s happening and bring new developers up to speed.
Our workflow starts with our annotation and curation tool. This is used by our staff to configure which sites should be visited on which frequencies, but unlike its predecessor, the Web Curator Tool, none of the more complex crawl processes are tightly bound inside it. All it does is provide a crawl feed, which looks like this:
[
{
"id": 1,
"title": "gov.uk Publications",
"seeds": [
"https://www.gov.uk/government/publications"
],
"schedules": [
{
"frequency": "MONTHLY",
"startDate": 1438246800000,
"endDate": null
}
],
"scope": "root",
"depth": "DEEP",
"ignoreRobotsTxt": false,
"documentUrlScheme": null,
"loginPageUrl": null,
"secretId": null,
"logoutUrl": null,
"watched": false
},
...
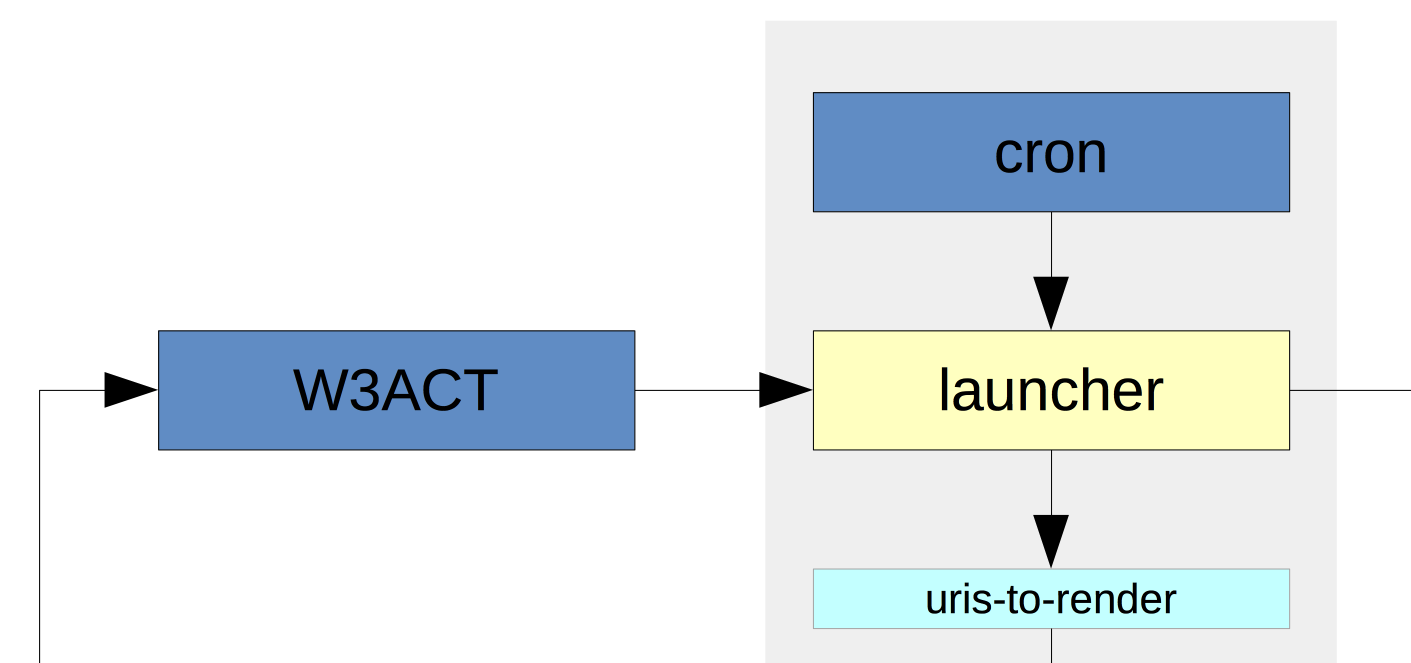
A separate launcher process runs every hour, downloads this feed, and checks if any crawls should be launched in the next hour. If so, it posts the seeds of the crawl onto a message queue called ‘uris-to-render’.2
{
"clientId": "FC-3-uris-to-crawl",
"isSeed": true,
"metadata": {
"heritableData": {
"heritable": [
"source",
"heritable"
],
"source": ""
},
"pathFromSeed": ""
},
"url": "https://www.gov.uk/government/publications"
}
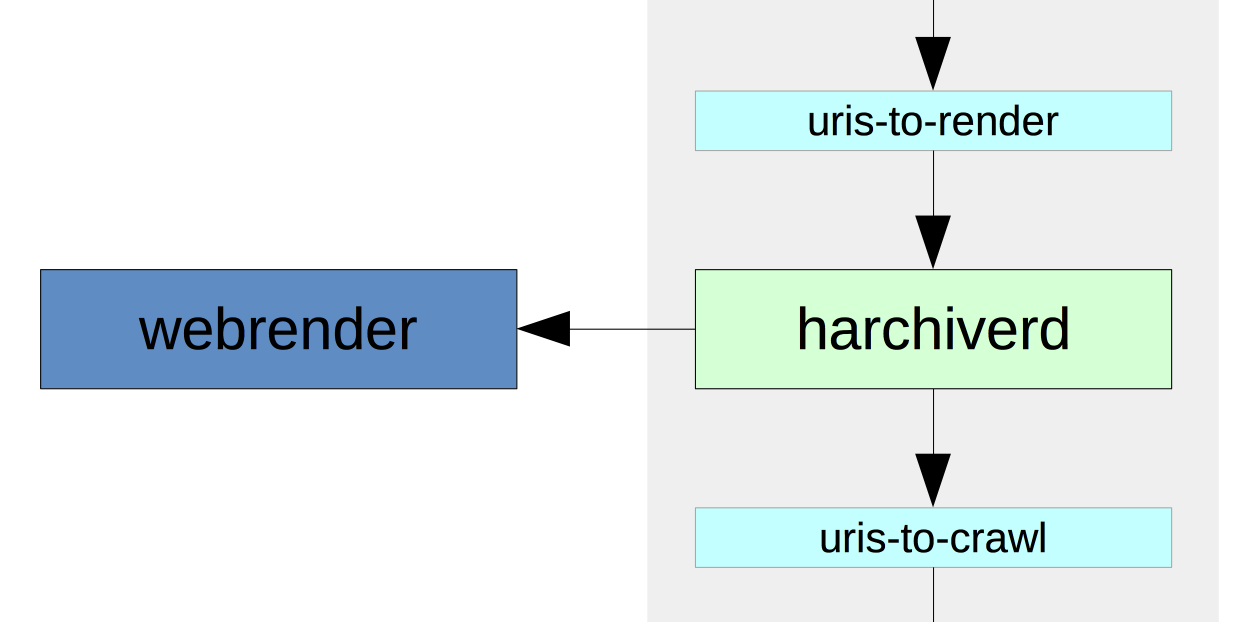
In this new workflow, the first actual crawl activity is now a browser-based rending step. Before we do anything else, we run the seeds through an embedded web browser and attempt to capture a good rendering of the original site. We keep the rendered pages, and extract the embedded and navigational links that we find. These URIs are then passed on to a ‘uris-to-crawl’ queue.
{
"headers": {},
"isSeed": true,
"method": "GET",
"parentUrl": "https://www.gov.uk/government/publications",
"parentUrlMetadata": {
"heritableData": {
"heritable": [
"source",
"heritable"
],
"source": ""
},
"pathFromSeed": ""
},
"url": "https://www.gov.uk/government/publications"
}
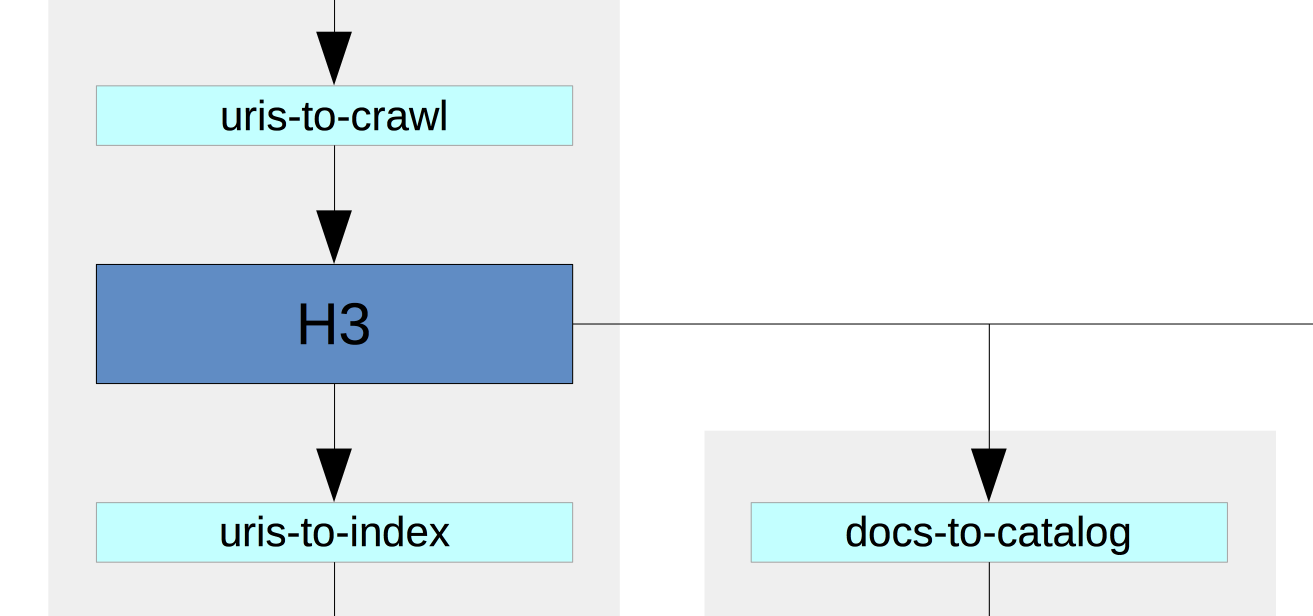
Our long-running Heritrix crawl is configured to pull messages off this queue and push the URLs into the crawl frontier. At this point, we have broken our rule of having small, simple processes, and we’re using Heritrix in quite a similar way to our earlier crawls. The way it runs and the way it queues and prioritises URLs has been modified to suite this continuous approach, but it’s still a rather uncomfortably monolithic chunk that manages a lot of crawl state in a rather difficult to monitor way.
To complete the workflow, we also configured Heritrix to push a message onto a ‘uris-to-index’ queue after each resource is crawled.
{
"annotations": "ip:173.236.225.186,duplicate:digest",
"content_digest": "sha1:44KA4PQA5TYRAXDIVJIAFD72RN55OQHJ",
"content_length": 324,
"extra_info": {},
"hop_path": "IE",
"host": "acid.matkelly.com",
"jobName": "frequent",
"mimetype": "text/html",
"seed": "WTID:12321444",
"size": 511,
"start_time_plus_duration": "20160127211938966+230",
"status_code": 404,
"thread": 189,
"timestamp": "2016-01-27T21:19:39.200Z",
"url": "http://acid.matkelly.com/img.png",
"via": "http://acid.matkelly.com/",
"warc_filename": "BL-20160127211918391-00001-35~ce37d8d00c1f~8443.warc.gz",
"warc_offset": 36748
}
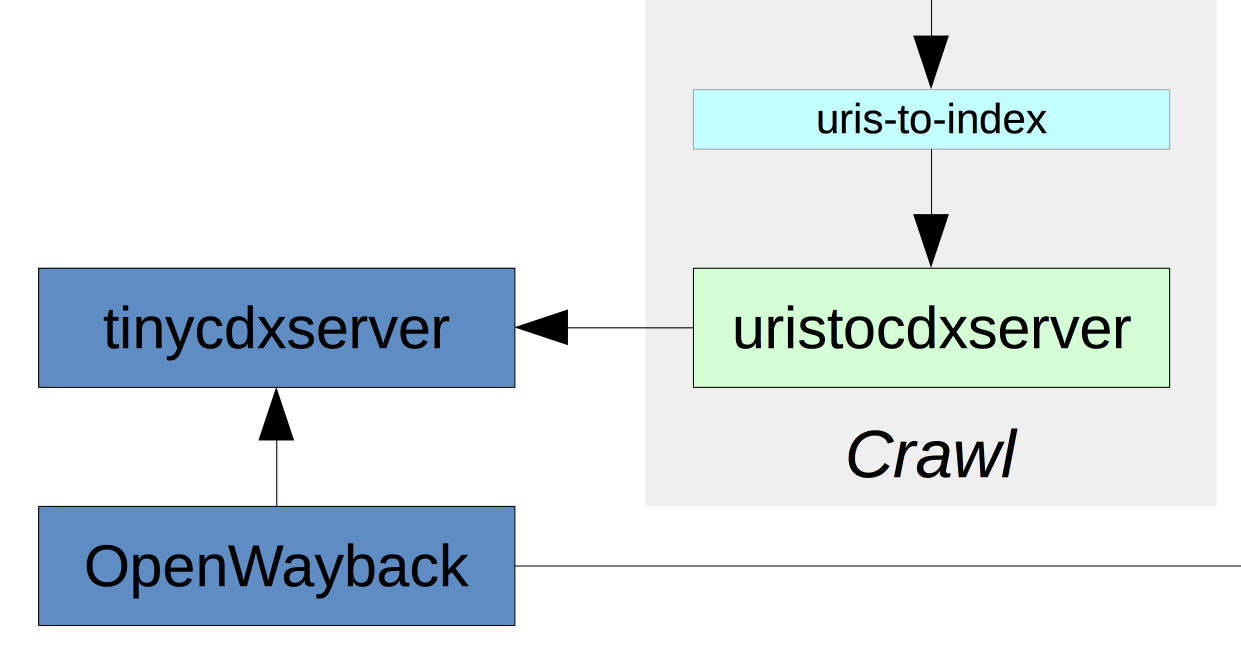
This is very similar to the Heritrix crawl log, but in the form of a stream of crawl event messages, which are then submitted to a dedicated CDX server. This standalone component developed by the National Library of Australia provides a clear API for both adding as well as querying CDX data, and can cope with the submission of many hundreds of CDX records per second.
Our QA OpenWayback is configured to use this real-time CDX server, and to be able to look at the WARC files that are currently being written as well as the older ones. This means that crawled resources become available in Wayback almost instantly.
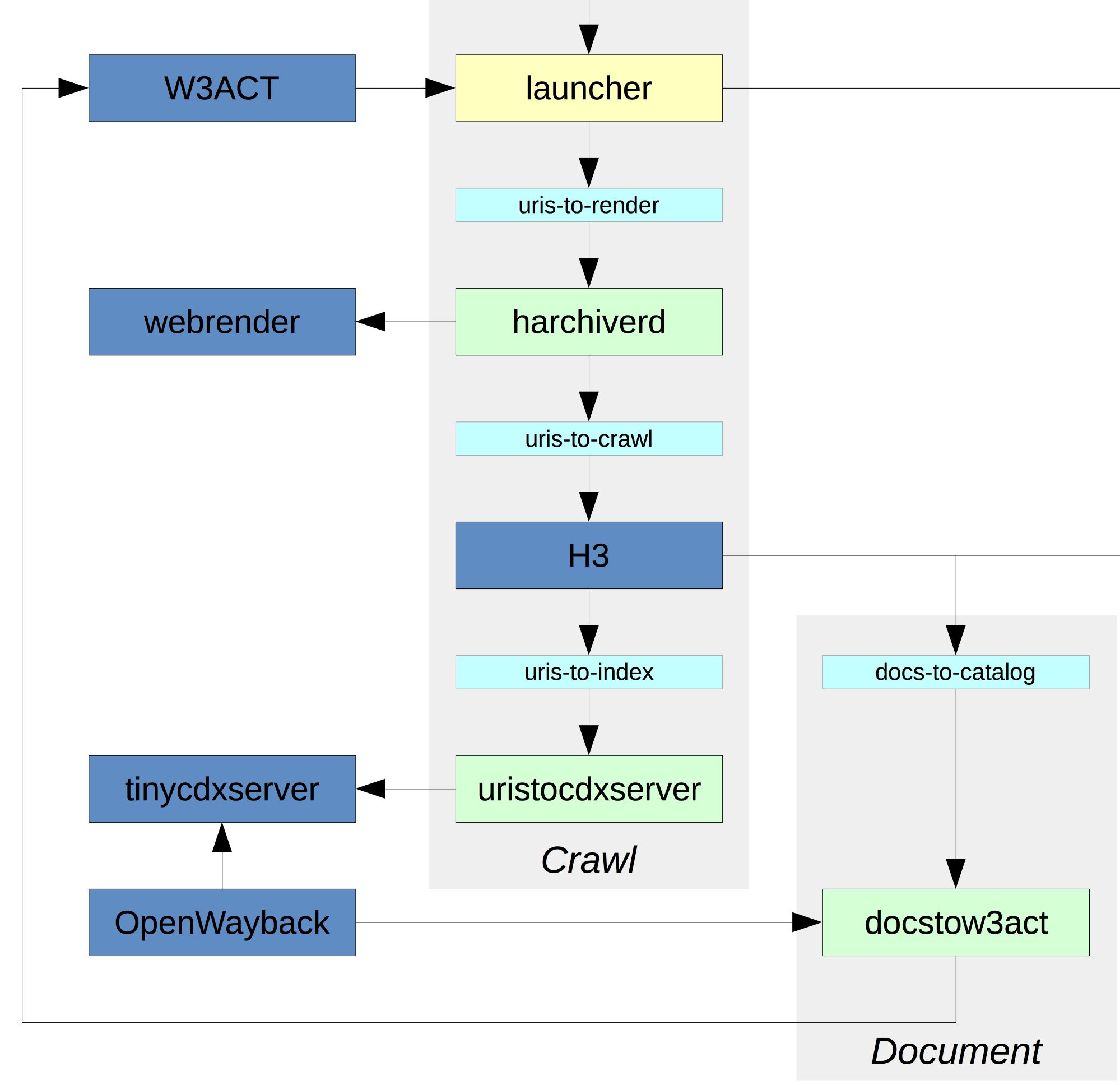
Under our previous crawl procedure, we were only able to update the CDX index overnight, so this live feedback is a big improvement for us. It also allows the part of the workflow that extracts documents from the crawl to check that they are available before passing them back to W3ACT for cataloguing.
Putting it all together, we have a more robust crawl system where, depending on the complexity of the page, the whole process of rendering, archiving and making a seed available can complete in seconds.

Smaller components are easier for our developers to work on, and it’s easy to scale up and tune the number of clients running at each individual stage. For example, if the system is under a lot of load, we can re-configure the number of web page renderers on the fly without bringing down the whole system.
Unfortunately, although leading with the web render step has improved things, it’s still not good enough.
We’ve got the stylesheet and more images for the BBC News homepage, but we’re still missing some of the images.
To really solve these issues, we need to capture the resources precisely as the embedded web browser received them, rather than downloading them once from and then passing the URLs to Heritrix to be downloaded again. We also need to be able to run more pages through browser engines, which means we need to find a way of making Heritrix itself more modular and scalable.
To summarise, out of that big list of “future challenges” from 2012, the most critical ones we are facing right now are:
- Incremental display mechanisms
- Especially multi-platform ‘responsive design’
- The
srcsetattribute is still not supported by Heritrix3 out-of-the-box
- Multi-sourced, embedded content
- Identifying embedded resources now requires JavaScript execution
- Need to run more pages through browsers
- Rich, streamed media
- Can often by captured, but tools are not integrated and storage and playback are problematic and unstandardised
- Paywalls
- The crawlers need to be able to login
And I’d now add to the list:
- SSL more and more common
- OpenWayback support for SSL is poor out-of-the-box
- and what of HTTP/2 around the corner?
I know many of you have already face many of these issues in various ways, and I’d love to hear about the different tactics that you’ve been using.
Because we (the British Library) need a big push to improve our tools, and we are running out of time. Fortunately, my organisation is willing to put some funding behind solving this problem over the next two years. But we’d really rather not do this alone.
Whatever we do will be open source, but I’d really much rather be part of an open source project. Our tools and our results will be much better if we can find ways of pooling our resources, but more importantly, I think many of us enjoy working with our peers in other organisations. Simply put, I think open source projects are more fun, especially when you’re working in a complex niche, like web archiving. I suspect most of us are working in small teams or as individuals in much larger organisations, and I believe we can work best when work together.
There is a whole conference track dedicated to Exploring Collaboration tomorrow, where we can spend time examining the ways this kind of collaboration might work. Please do come along if you’re interested in building tools together.
Thank you.