
During the last quarter of 2021, the technical services that make up the web archive underwent lot of changes behind the scenes. These changes should help us to improve our services, so it’s worth explaining a little about what’s been going on.
- TOC {:toc}
Starting the Hadoop 3 Migration #
Our Hadoop cluster is now quite old, and updating this to a newer version has been a long-standing issue. The old Hadoop version no longer gets updates, and is not supported by modern tools and libraries, which prevents us from making the most of what’s available.
For a long time, it was unclear how best to proceed – an in-place update seemed too risky, but a cluster-to-cluster migration appeared to require too much hardware. So, over recent years, we have spent time learning how to set up and maintain a Hadoop 3 cluster, and evaluating different migration strategies, focusing on how we might maintain service during any migration.
We eventually decided a cluster-to-cluster migration should be possible, as long as we can purchase higher-density storage so we have enough headroom to migrate content over ahead of migrating hardware. Earlier in the year, following some procurement delays, we were able to purchase and establish this new Hadoop 3 cluster, with each server providing over 450TB of raw storage (compared to about 85TB per server for the older cluster).
While this was being set up, we also had to generalize our services so that all important process can be run across both clusters, and that WARC records can be retrieved from either. This has been quite time-consuming, but as 2021 drew to a close (and space on the older cluster was getting tight!), we were finally able to shift things so that newly-harvested content is written to the new Hadoop 3 cluster.
Behind the scenes, our file tracking database was updated to scan both clusters and act as a record of which files are where, and to update this record hourly rather than just once per day. A new WARC Server component was created that takes Wayback request for WARC records, and uses the tracking database to work out which cluster they are on, and then grabs and returns the WARC record in question.
In the future, the tracking database will be used to help orchestrate the movement of content to Hadoop 3, with hardware being shifted over as it becomes available. The new WARC Server means that we will be able to maintain an uninterrupted service throughout.
But to avoid interruption now, we also needed to enable access to the newer content on Hadoop 3 by indexing it for playback. To this end, a new CDX indexer implementation has been created that can be run on either cluster (built with Webrecorder’s Python tools rather than Java) . As before, the tracking database is used to keep track of what’s been indexed, but both clusters can now be indexed promptly.
Similarly, although not fully moved into production yet, the Document Harvester document extractor and the Solr full-text indexing tasks have been re-written to be able to run on either cluster, and be more robust than the prior implementations.
At time time of writing, the main public website and the internal Storage Report have not been fully moved over to run across both systems, so there may be some slight inconsistencies there in the short term. However, we expect to resolve this in the next week or two.
Task Orchestration via Apache Airflow #
This large set of changes has also been used as an opportunity to update how our critical web-archiving tasks are implemented and orchestrated. We were using the Luigi framework to define tasks and their dependencies, but over time we have found this to be problematic in a number of ways:
- The code that performs tasks and the code that orchestrates those tasks were mixed together in the same source files. This made it very hard to work on improving any individual task on it’s own, and made testing difficult.
- The Luigi task scheduling seems to be unreliable, with processors occasionally getting stuck and not making any progress, or not raising any errors on failure. This particularly affected the Document Harvester, leading to a number of outages.
- The Luigi task management interface is not very useful. It does not make it easy to look at previous runs, and presents very little detail.
- The way Luigi encourages task dependencies to be coded makes it very difficult to clear out those dependencies so task can be re-run.
Therefore, while updating the various web archive tasks, they have been modified to run under Apache Airflow.
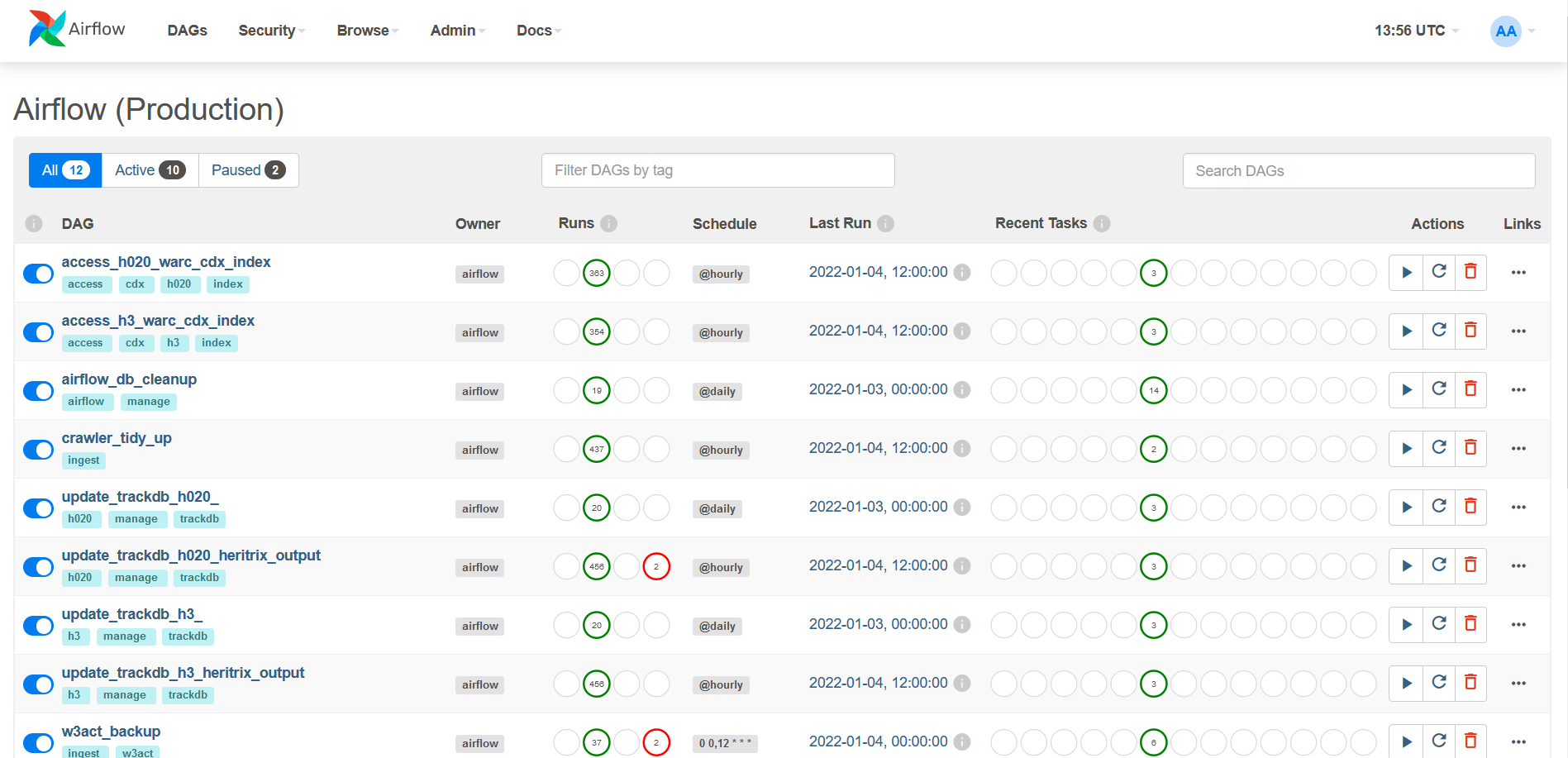
This is a popular and very widely used workflow definition and scheduling system, with both Google and Amazon offering Airflow as a fully-managed cloud services as well as a healthy open source community around it. Along with this choice of workflow platform, we have also chosen to implement each task tool as a separate standalone Python command-line program. This means:
- Task code is separate from orchestration, can be developed independently, and tasks can be deployed as Docker containers, which keeps the underlying software dependencies apart.
- We get to use the Airflow scheduler, which appears to be more reliable, will warn us when tasks get stuck or fail, and provides Prometheus integration for monitoring.
- The Airflow Web UI is very detailed, allows access to task logs, summaries of runs and statistics, makes workflow management easier, and provides a framework for documenting each workflow.
- The Airflow Web UI also makes it easy to clear the status of failed workflow runs so they can be re-run as needed.
Over time, we expect to move all web archiving tasks over to this system.
W3ACT #
There only have been minor updates to the W3ACT curation service lately, rolled out towards the end of December.
- QA Wayback is now running PyWB version 2.6.3 for improved playback (e.g. ukwa-pywb#70).
- Improvements to how the W3ACT authentication cookie is handled, resolving w3act#662.
Website #
Most of the recent work on the website user interface has focused on improving the presentation of our large set of curated collections by grouping them into categories. This work is still being discussed and developed internally, so isn’t part of the public website yet. However, we’re making good progress and hope to release a new version of the website over the coming weeks.
Apart from the interface itself, some additional work has been done to update the internal services (e.g update PyWB to version 2.6.3 and add the WARC Server to read content from both Hadoop clusters), and move the deployment to our newer production platform. As indicated above, these updates should be rolled out shortly.
2021 Domain Crawl #
As in 2020, the 2021 Domain Crawl was run on the Amazon Web Services cloud. This time, following improvements to Heritrix and building on prior experience, the crawl ran more smoothly and efficiently than in 2020, using less memory and disk space for the crawl frontier. The crawler was started up early in August for penetration testing, and then taken down while the security concerns were addressed. The actual crawl began on the 24th of August, starting with 10 million seed URLs, and the vast majority of the crawl had completed by mid-November. Most of the 27 million hosts we visited were crawled completely, but ~57,200 hosts did hit the 500MB size cap. However, some of these were content distribution networks (CDNs), i.e. services hosting resources for other sites, so some caps were lifted manually and the crawl was allowed to continue.
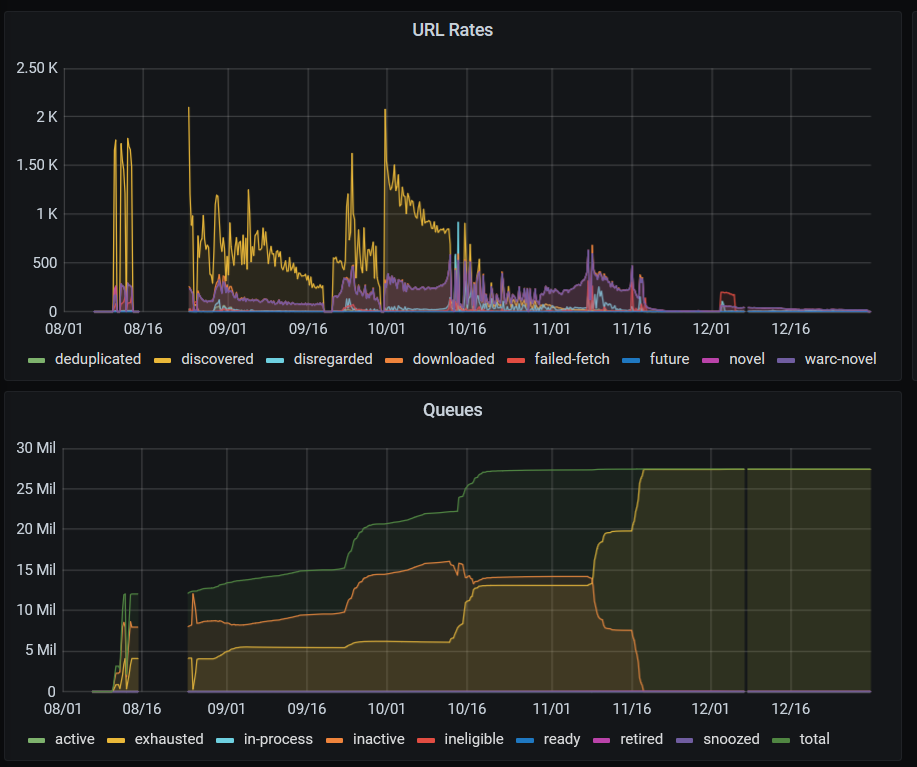
On the 30th of December, the crawl was stopped, having processed 2.04 billion URLs and downloaded 99.6 TB of data (uncompressed). However, a lot of the CDN content remained uncollected, and would take a very long time to collect under Heritrix’s normal ‘politeness’ rules. In the future, it would be good to find a way to allow Heritrix to crawl these sites much more quickly, without having to manually intervene to decide which hosts are CDNs.
At this time, it has not been decided whether the 2022 Domain Crawl will be run in the cloud or from Boston Spa. Either way, we expect to begin the process of transferring domain crawl 2020/2021 content from AWS to our Hadoop 3 cluster over this next year.
Upcoming work #
In the next quarter, as well as the future updates outlined above, we are also expecting to:
- Receive hardware for the additional Hadoop 3 replication cluster, then start setting it up and populating it ahead of it being transferred to the National Library of Scotland later in the year.
- Improve monitoring of the process of moving WARCs and logs to Hadoop (in part to ensure we spot problems with the Document Harvester earlier).
- Add improved reporting services, replacing the current Storage Report with one that is up-to-date and runs across both clusters (ukwa-notebook-apps#12).
- Integrate static documentation and translations into the main website, via a simple CMS (ukwa-services#48). This will make it easier to add more pages and manage the translation of those pages to/from Welsh and Scottish Gaelic.
- Begin implementing the NPLD Player, which we need in order to improve reading-room access across the Legal Deposit libraries. We’re currently finalizing the details of how our external partner will help us do this, and more details will be made available over the next couple of months.