
First published as this UK Web Archive blog post
This is a summary of what’s been going on since the 2023 Q1 report.
The 2023 Domain Crawl #
At the end of the last quarter, we launched the 2023 Domain Crawl. This started well (as described in the 2023 Q1 report) but a few days later it became clear the crawl was going a bit too well. We were collecting so quickly, we started to run out of space on the temporary store we use as a buffer for incoming content.
The full story of how we responded to this situation is quite complicated, so I wrote up the detailed analysis in a separate blog post. But in short, we took the opportunity to move to a faster transfer process and switch to a widely-used open source tool called Rclone. After about a week of downtime, the crawl was up and running again, and we were able to keep up and store and index all the new WARC files as they come in.
Since then, the crawl has been running pretty well, but there have been some problems…
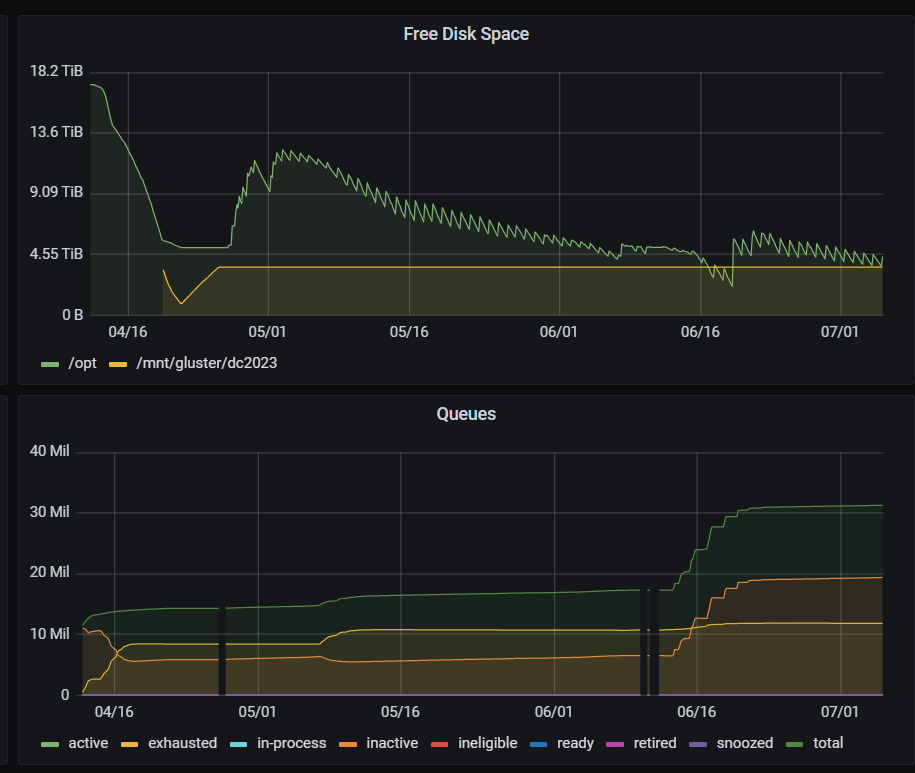
The crawler uses disk space in two main ways: the database of queues of URLs to visit (a.k.a. the crawl frontier), and the results of the crawl (the WARCs and logs). The work with Rclone helped us get the latter under control, with the move from /mnt/gluster/dc2023 to sharing the main /opt drive and uploading directly to Hadoop. These uploads run daily, leading to a saw-tooth pattern as free space gets rapidly released before being slowly re-consumed.
But the frontier shares the same disk space, and can grow very large during a crawl. So it’s important we keep an eye on things to make sure we don’t run out of space. In the past, before we made some changes to Heritrix itself, it was possible for a domain crawl to consume huge amounts of disk space. Once, we hit over 100TB for the frontier, which becomes very difficult to manage. In recent domain crawls, our configuration changes we’ve managed to get this down to more like 10TB.
But, as you can see, around the 13th of June, we hit some kind of problem, where the apparent number of queues in the frontier started rapidly increasing, as did the rate at which we were consuming disk space. We deleted some crawler checkpoints to recover some space, as we very rarely need to restart the crawl from anything other than the most recent daily checkpoint, but this only freed-up modest amounts of space. Fortunately, the aggressive frontier growth seemed to subside before we ran out of space, and the crawl is now stable again.
Unfortunately, it’s not clear what happened. Based on previous crawls, it seems unlikely that the crawler suddenly discovered many more millions of web hosts at this point in the crawl. In the past, the number of queues has been consistently up to around 20 million at most, so this leap to over 30 million is surprising. It is possible we hit some weird web structures, but it’s difficult to tell as we do don’t yet have reliable tools for quickly analysing what’s going on in this situation.
Suspiciously, just prior to this problem, we resolved a different issue with the system used to record what URLs had been seen already. This had been accidentally starved of resources, causing problems when the crawler was trying to record what URLs had been seen. This lead to the gaps in the crawl monitoring data just prior to the frontier growth, as the system stopped working and required some reconfiguration. It’s possible this problem left the crawler in a bit of a confused state, leading to mis-management of the frontier database. Some analysis of the crawl will be needed to work out what happened.
UKWA Website URL Search #
In the laster quarter, the new URL search feature was deployed on our BETA service. Following favourable feedback on the new feature, the main https://www.webarchive.org.uk/ service has been updated to match. We hope you find the direct URL search useful.
We’ve also updated the code that recognises whether a visitor is in a Legal Deposit reading room, as it wasn’t correctly identifying readers at Cambridge University Library. Finally, there was an issue with how the CAPTCHAs on the contact and nomination forms were being validated, which has also been resolved.
Legal Deposit Access Service #
Our colleagues from Webrecorder delivered the initial set of changes to the ePub renderer, making it easier to cite a paragraph of one of our Legal Deposit eBooks. Given how long the ePub format has been around, it is perhaps surprising that support for ‘obvious’ features like citations and printing are still quite immature, inconsistent and poorly-standardised. To make citation possible, we have ended up adopting the same approach as Calibre’s Reference Mode and implemented a web-based version that integrates with out access system.
We’ve also worked on updating the service documentation based on feedback from our Legal Deposit Library partners, resolved some problems with how the single-concurrent-use locks were being handled and managed, and implemented most of the translations for the Welsh language service. The translations should be complete shortly, and and updated service can be rolled out, including the second set of changes from Webrecorder (focused on searching the text of ePub documents).
Replication to NLS #
The long process of establishing a replica of our holdings at the National Library of Scotland (NLS) is finally nearing completion. We have an up-to-date replica, and have been attempting to arrange the transfer of the servers. This turned out to be a bit more complicated that we expected, so has been delayed, but should be completed in the next few weeks.
Minor Updates #
For curators, one small but important fix was improving how the W3ACT curation tool validates URLs. This was thought to have been fixed already, but the W3ACT software was not using URL validation consistently and this meant it was still blocking the creation of crawl target records with top-level domains like .sport (rather than the more familiar .uk or .com etc.). As of June 23rd, we released version 2.3.5 of W3ACT that should finally resolve this issue.
Apart from that, we also updated Apache Airflow to version 2.5.3, and leveraged our existing Prometheus monitoring system to send alerts if any of our SSL certificates are about to expire.